Un modèle de fondation qui décrypte le cerveau.
Diagnostics neurologiques assistés par IA.
100 M de paramètres · +1 milliard de tokens · + de 100 000 EEG
Le Large Brain Model est le modèle de fondation auto-supervisé de BIOSerenity pour l’électroencéphalographie clinique. Une architecture pré-entraînée, affinée pour l’ensemble des diagnostics neurologiques, de la détection de crises à la classification des pathologies, avec jusqu’à 20 fois moins de données annotées que le deep learning classique.
Temps de lecture estimé : 5 minutes
Un modèle de fondation qui décrypte le cerveau.
Diagnostics neurologiques assistés par IA.
100 M de paramètres · +1 milliard de tokens · + de 100 000 EEG
Le Large Brain Model est le modèle de fondation auto-supervisé de BIOSerenity pour l’électroencéphalographie clinique. Une architecture pré-entraînée, affinée pour l’ensemble des diagnostics neurologiques, de la détection de crises à la classification des pathologies, avec jusqu’à 20 fois moins de données annotées que le deep learning classique.
Temps de lecture estimé : 5 minutes
Un modèle de fondation qui
décrypte le cerveau.
Diagnostics neurologiques assistés par IA.
100 M de paramètres · +1 milliard de tokens · + de 100 000 EEG
Le Large Brain Model est le modèle de fondation auto-supervisé de BIOSerenity pour l’électroencéphalographie clinique. Une architecture pré-entraînée, affinée pour l’ensemble des diagnostics neurologiques, de la détection de crises à la classification des pathologies, avec jusqu’à 20 fois moins de données annotées que le deep learning classique.
Temps de lecture estimé : 5 minutes
Qu’est-ce que le LBM ?
Un lecteur d’EEG
qui a d’abord appris le langage du cerveau.
Les modèles d’IA modernes pour les signaux médicaux nécessitent généralement des milliers d’exemples étiquetés par des experts pour être utiles, un goulot d’étranglement qui freine la neurologie depuis une décennie.
Le Large Brain Model emprunte une voie différente, issue de la même famille de techniques qui nous ont donné GPT et AlphaFold : le pré-entraînement auto-supervisé. Au lieu de se faire dicter la signification de chaque EEG, le LBM analyse des centaines de milliers d’heures d’activité cérébrale brute et doit compléter les parties masquées du signal.
Au fil du temps, il construit une grammaire interne de ce à quoi ressemble l’activité cérébrale : la forme du sommeil, le rythme de la concentration, la propagation des ondes EEG, sans que personne ne lui apprenne les étiquettes.
Il apprend à quoi ressemble l’activité cérébrale
avant même d’apprendre comment la nommer.
Une fois cette architecture établie, elle devient un point de départ universel. Une nouvelle tâche clinique, détection d’événements épileptiques, analyse du sommeil, signalement d’un enregistrement anormal, ne nécessite qu’une légère couche d’ajustement (fine-tuning) et une petite quantité de données étiquetées.
Le résultat est un modèle unique dont les bénéfices se cumulent. Chaque nouvel hôpital, chaque nouveau jeu de données, chaque nouvelle tâche rend la suivante moins coûteuse, plus rapide et plus précise à déployer.
Architecture
Pré-entraîner. Ajuster. Déployer.
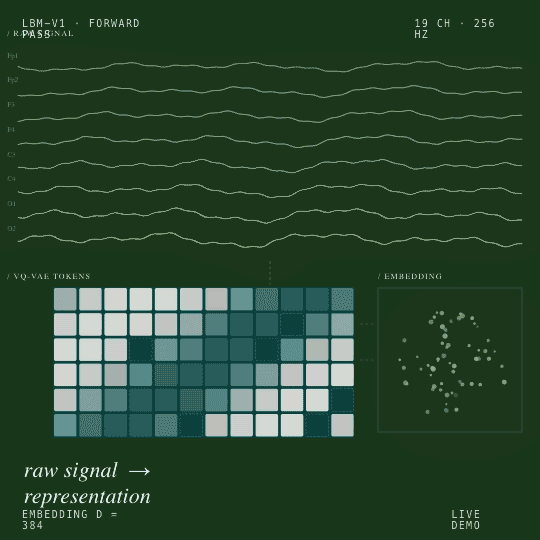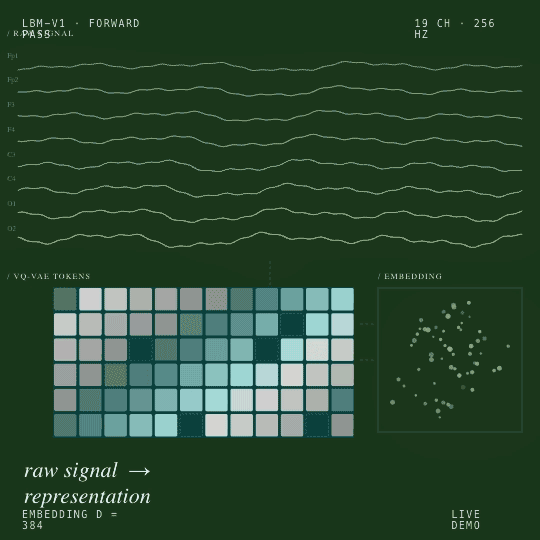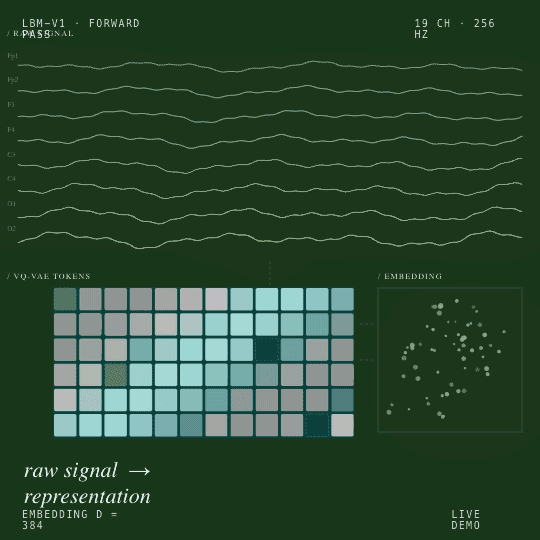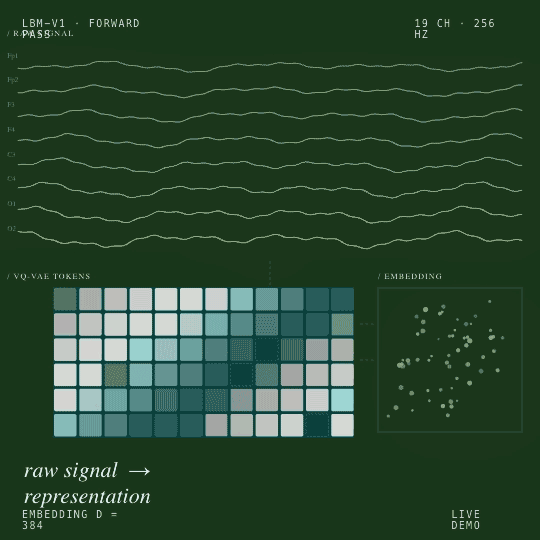
Un pipeline auto-supervisé en deux phases, tokenisation VQ-VAE suivie d’une prédiction spectrale masquée, produit un plongement (embedding) de 384 dimensions qui se généralise à toutes les tâches EEG en aval que nous avons testées.






Performance
L’état de l’art pour
chaque tâche clinique mesurée.
Tâche T1 · Détection de crises
0,926 AUROC
Détection d’événements critiques
+ État de l’art sur TUSZ
Tâche T2 · Normal / Anormal
0,970 AUPRC
Tri au niveau de l’enregistrement
+ Bettinardi et al. 2025
Tâche T3 · Classification des anomalies
0,730 F1
Pathologie multi-classes
+ 6 catégories cliniques
Régimes à faibles données
+ 2-17%
Amélioration par rapport au DL classique
+ Sur toutes les tâches testées
Jusqu’à 20 fois moins de données annotées,
même précision.
L’auto-supervision modifie fondamentalement l’économie de l’étiquetage. Sur les benchmarks internes, les têtes LBM ajustées atteignent les performances des références classiques de deep learning avec une infime fraction des données EEG annotées par des experts, réduisant ainsi drastiquement le temps et le coût de mise sur le marché d’un nouveau diagnostic.

Avantage stratégique
Le volant d’inertie des données (data flywheel) que personne d’autre ne possède.
Modèle de fondation auto-supervisé pour l’électroencéphalogramme médical.
/ 01 — Corpus propriétaire
100,000+
EEG cliniques exploitables
Acquis via le réseau de dispositifs et de services propres à BIOSerenity. Organisés, anonymisés, de qualité médicale.
/ 02 — Intégration verticale
Dispositif x IA
Maîtrise de bout en bout
Matériel Neuronaute+ & EpiPhy, pipeline d’acquisition, modèles d’IA, rapports cliniques – le tout sous un même toit.
/ 03 — Avance réglementaire
CE IIb
SaMD · MDR · Prêt pour l’IA Act
Système qualité IEC 62304 · ISO 13485. Expérience concrète de l’homologation européenne des biomarqueurs d’IA.